This article is more than 1 year old
'MongoDB ate my containers!'
Plus: How to rack up a huge supercomputer bill using rsh
Line Break Welcome back to The Register's weekly software bug parade, Line Break: Season Two.
After a hiatus, and a vacation here or there, Line Break has been recommissioned. You can catch up on previous episodes, here. The idea is simple: if you spot buggy code in the wild that's driven you bonkers or to hysterics, drop us a line with the details, and we'll share your story with Reg readers. It's all one big learning experience. If you wish to remain anonymous, let us know: we always protect our sources.
MongoDB: The Snapchat for databases
We'll kick things off with this yarn spotted by your humble hack. David Glasser, a Meteor core developer, has detailed this week how programmers can trigger a data race condition when using open-source NoSQL darling MongoDB.
If you search a MongoDB database for entries, you get back a cursor, which points to the first entry in the set of results. You then iterate the cursor to obtain each result in the set one by one. So far so good. Except, according to Glasser, if an update happens during the iteration, an entry that should be in the set could be whipped out before the query thread has a chance to see it.
The end result? MongoDB queries don't always return all matching documents.
"When I query a database, I generally expect that it will return all the results that match my query," Glasser blogged on Tuesday.
"Recently, I was surprised to find that this isn’t always the case for MongoDB. Specifically, if a document is updated while the query is running, MongoDB may not return it from the query — even if it matches both before and after the update! If you use MongoDB, you should be aware of this subtle edge case and make sure your queries don’t fall victim to it."
In Glasser's case, his code searched a database of metadata describing a platform's software containers; this metadata would describe a container as healthy or unhealthy, for example. Glasser noticed some containers would, bizarrely, vanish in one query and reappear in another. After some investigation, he found this in the MongoDB documentation:
Reads may miss matching documents that are updated during the course of the read operation.
In other words, this is what was happening: the software was iterating a cursor, moving through the containers one by one; meanwhile, one of the containers would be updated from unhealthy to healthy status, changing its position in an index; that update would move the altered entry to before the current query result position, so it would never be returned by the iterated cursor, thus disappearing the container from the search results.
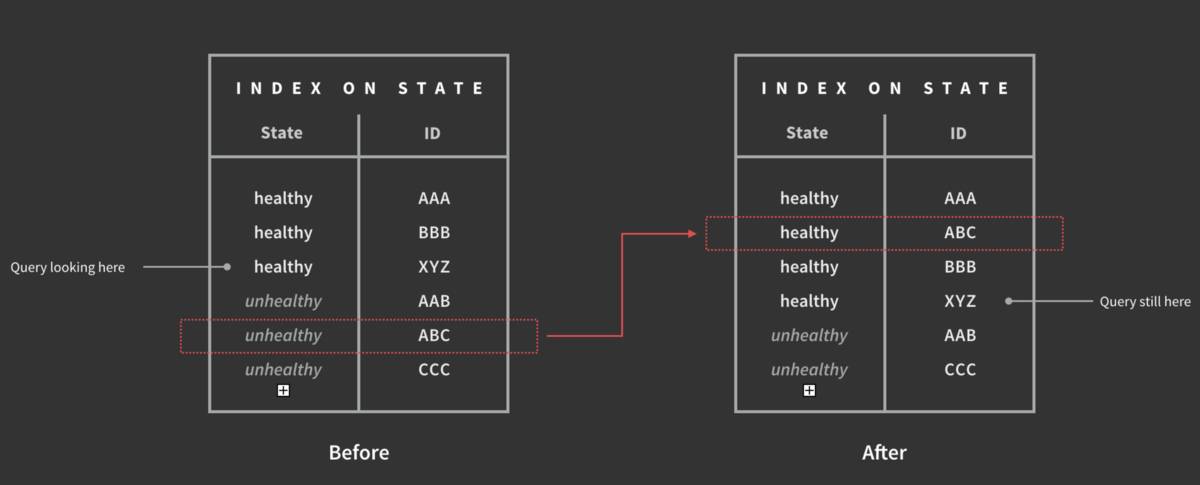
Leap ... David Glasser's illustration of the problem (click to enlarge)
"When running this query 100,000 times or so a day, we’d hit the bug every few days," added Glasser.
Moral: This is why locking is useful. It's also why plenty of other databases packages exist. Either write your software with the above race condition in mind, or pick another database system – maybe a SQL database is really what you need, not a loose NoSQL system.
(By the way, Kelly Stirman, VP of strategy at MongoDB, told us: "MongoDB clearly outlines the isolation guarantees of our database in our documentation. It is possible to employ data modeling and indexing techniques that work with the isolation levels we provide, which the author noted he was able to do. o be clear, this user’s containers were not ‘eaten’ and no data was lost.")
That's Cray-z talk
A reader we'll refer to as Tom gave us this tale of a supercomputer center and an errant use of rsh – a tool typically used to execute commands in a shell on a remote machine. In this case, the remote machine was ... a rather expensive Cray supercomputer. This beast was running rshd, allowing users on workstations to run rsh, connect in, and issue commands on the super.
As Tom explains:
This was the mid-1990s at one of the largest computing centers of the country. Those were the times where Cray Research was the leader of supercomputing, with their vector machines, based on gallium arsenide, liquid cooling, and so on. In a nutshell, a supercomputer was dead expensive to run. My first job was to learn TCL/TK and come up with a graphical reporting tool in order to know which programs used how much computing power on a big super.
Bam: two days after, the tool was ready, and I ran it against last month's Unicos (Cray's Unix) reporting data. It turned out the number-one consumer – using 50 per cent of the monthly computing power of the system – was rshd.
After some severe head scratching with the sysadmin, we concluded there was no way
rshdcould have burned so much power. Except, as it turned out, when some moron junior dev implements a computing loop as follows, running on his local workstation:
for(X=0; X < MAX; X++)
{
system("rsh supercomputer:./iteration");
}
MAX being in the range of dozens of millions, and
./iterationbeing an algorithm requiring only worth 20ms of computing time. The calling program was taking 20s to log in every time, in order to actually complete only 20ms of actual work.It's still a mystery to me why this bloke thought it was a good idea to rsh-spam this supercomputer, for one freaking month, rather than run the darn thing entirely on the said super or even his workstation.
But wait – there's more.
Second story, same big computing center: one of my colleagues had a problem with some incoherent results coming from his supercomputer calculations. This was happening very rarely on some test datasets. At that time, we were all connected to a central
sendmailsystem to read and send emails via Emacs and XEmacs. The supercomputers were also connected to thissendmailinstance.So sure enough, to debug the problem, my mate updated his program on the super, as follows:
for(X=0; X < MAX; X++)
{
calculation();
if(special_condition)
{
system("cat /tmp/data | mailx -s ERROR X.Y@mydomain.com");
}
}
What could go wrong, eh, since
special_conditiononly happened two or three times out of millions of iterations on the test datasets? Well, once the tests were carried out, the program was run using live data. And I think you guessed it: on the live dataset,special_conditionwas true every single iteration – millions of them.We had a nice afternoon, that day, free of any email nuisance.
Presumably because sendmail had to be killed. Which should be the standard operating mode for sendmail. Thanks, Tom. You know who you are. Moral: Watch your overheads – don't waste seconds queuing up code that takes fractions of a second. And put some sort of rate-limit on error logging while debugging code, or you'll suffer information overload.
Don't forget to drop us your tales (PGP details if needed) or post in the comment section below. Tune in this time next week for more garbage in, garbage out. ®
