This article is more than 1 year old
A looksee into storage upstart Hedvig's garage
Quick dip under a distributed storage platform's covers
+Comment Hedvig decloaked from stealth recently, saying it’s producing converged block, file and object storage for enterprises with Facebook/Amazon-level scale, costs and efficiencies.
It does this through its DSP (Distributed Storage Platform) software, and The Reg was at a June 23 press briefing in Santa Clara to hear more.
Founder and CEO Avinash Lakshman dismissed most storage innovation over the past decade as mere tweaking. "Amazon and Facebook" he said, "gave me the experience to enable a fundamental innovation for storage." That experience included building Amazon's Dynamo NoSQL precursor, and Cassandra for Facebook.
Facebook Cassandra had 100 million users on petabyte-scale cluster operated by just 4 people, including Avinash. So he can build extreme scale-out storage systems that run reliably on commodity hardware and need sparse administration efforts.

Hedvig founder and CEO Avinash Lakshman
His bet is that enterprises will increasingly need the same type of storage and Hedvig is his vehicle for delivering it. What's involved?
A cluster of commodity servers, with local flash and disk media, and Hedvig distributed storage SW in a nutshell.
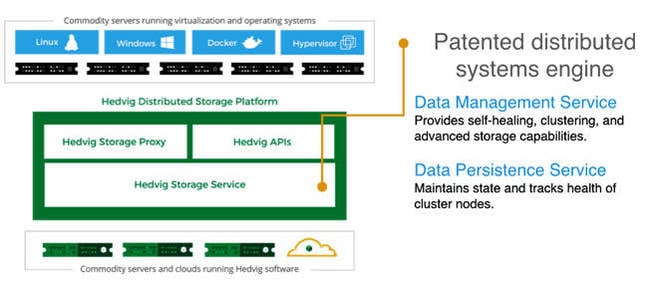
Hedvig DSP slide from its deck
What we have is a 2-layer piece of software with a Hedvig Storage Service (HSS) being the media interface, and the upper layer is split into a Hedvig Storage Proxy and a set of Hedvig APIs. Pretty straightforward so far, except that the servers can be either X86 or ARM-based.
We were told by Hedvig marketing veep Rob Whitely: "Facebook and Amazon are marching towards ARM and flash."
One platform replaces the need for separate block, file, object, cloud, replication, backup, compression, deduplication, flash, and caching equipment. Each capability can be granularly provisioned in software on a per-Virtual Disk basis to suit your unique workloads.
Hedvig Storage Service
The HSS provides a data management service with self-healing, clustering, and advanced storage capabilities. Its data persistence service maintains state and tracks the health of cluster nodes. It forms an elastic cluster using any commodity server, array, or cloud infrastructure.
It "operates as an optimized key value store and is responsible for writing data directly to the storage media. It captures all random writes into the system, sequentially ordering them into a log structured format that flushes sequential writes to disk. This provides the ability to ingest data at a high rate, as well as optimize the disk utilisation."
It consists of two primary processes:
- Data process ... responsible for the layout of data on raw disk.
- Hedvig storage nodes create two units of partition: storage pools, a logical grouping of three disks in the node, and containers, 16 GB chunks of data.
- Virtual Disks are divided into containers, each residing in a unique storage pool in a given storagenode.
- Containers are replicated based on the replication policy associated with the Virtual Disk.
- Metadata process ... responsible for how and where data is written.
-
- Metadata tracks all reads and guarantees all writes in the system, noting the container, storage pool, replica, and replica locations of all data.
- Metadata is a key component of the underlying storage cluster, but is also cached by the Hedvig Storage Proxy, enabling metadata queries from the application host tier without traversing the network.
Virtual disk data gets sliced into chunks or containers and spread around actual disks. A chunk/container is 16GB in size, and can be shared by multiple virtual disks. Whitely said: "We can rebuild a failed 4TB physical drive in under 20 minutes by reconstituting its data from replicas. A RAID method would require hours."
Virtual disk can be of any size and the user doesn't see the 16GB container. There can be from one to six copies of data, depending on a user's choices.
Deployment
The Hedvig Storage Proxy presents block, file, or object via a VM or Docker container to any compute environment.
Every storage asset should have its own unique set of policies driven through APIs.
Whitely said: "Everything is thinly provisioned. We offer inline dedupe, compression (both global), snapshots, and clones. Turn on and off by app." He told us Nutanix inline dedupes by default and so can waste resources deduping stuff that can't be deduped.
The system can be deployed as hyperscale storage, that scales storage nodes independent from application hosts. Alternatively it can be used in a hyper-converged way, which scales storage nodes in lock-step with application hosts. It can be deployed on-premises or in a public cloud.
In fact both deployment styles can be based on the same Hedvig cluster.
There can be from two to thousands of nodes in a Hedvig storage cluster.
Application hosts can be physical server apps, server apps in VMs, or server apps in the cloud, and come in to the Hedvig storage cluster via iSCSI blocks, NFS files, or S3 and Swift objects. The system is agnostic to any hypervisor, container, or OS.
Applications see Hedvig virtual disks, which provide a scalable abstraction layer for granular provisioning of enterprise storage functions.
Data access characteristics
Think of Hedvig's DSP working like this:
- Admin provisions Virtual Disk with storage policies via UI, CLI, or API
- Virtual Disk presents block, file, and object storage to Storage Proxy
- Storage Proxy captures guest I/O and communicates to underlying cluster
- Storage Service distributes and replicates data throughout cluster
- Storage Service auto-tiers and balances across racks, data centers, and clouds
Hedvig management SW in action
Capacity and performance can grow or shrink dynamically and seamlessly, Hedvig says. Provisioning is simple. Per-volume granularity is claimed to be ideal for multi-tenancy, with platform APIs for orchestration and automation.
A Hedvig tech overview white paper (12-page PDF) says "the Hedvig user interface provides intuitive workflows to streamline and automate storage provisioning. Admins can provision storage assets from any device and bring the simplicity of public clouds to datacenter operations."
Hedvig claims the DSP is a superset of current storage styles such as virtual SANS, software-defined storage, hyper-converged system storage and storage arrays. It "seamlessly bridges and spans private and public clouds, easily incorporating cloud as a tier and DR (disaster recovery) environment."
Register comment
I think we can take it that Hedvig can build this software product. Whether enterprise storage customers are ready for it is another matter. Suggested use cases are storage for any hypervisor in a server virtualization environment, private cloud, and Big Data – pretty generic.
Hedvig says its platform "is a good fit for environments where explosive growth in data is affecting a company's bottom line – in terms of the cost-per-bit to store the data as well as the operational overhead of managing the storage infrastructure. It is also an ideal solution for companies deploying private and hybrid clouds where time-to-market and innovation are key requirements."
There are few greenfield storage deployments, and Hedvig is banking on the cost and admin complexity pain of existing storage deployments encouraging enterprises to look its way and try out its software in a POC or pilot.
The product should support SMB by the end of year. It's in limited availability now, with GA following in the not-so-distant future. Hedvig told us dedupe doesn't work with VMware cluster file system; it's disabled. Also there is no HDFS support. Maybe this is in its roadmap.
Feed your own Hedvig curiosity here. The Tech Overview whitepaper is thoroughly recommended. ®
